Neural Network: How does it work?

Curious about neural networks and deep learning? This post will inspire you to get started in deep learning. Why are we witnessing this kind of build up for neural networks? It is because of their amazing applications. Some of their applications include image classification, face recognition, pattern recognition, automatic machine translation, and so on. So, let’s get started now.
Machine Learning is a field of computer science that provides computers the capability to learn and improve from experience without being programmed explicitly. Deep learning is a form of machine learning that uses a computing model that is highly inspired by the structure of the brain. Hence, we call this computing model as a Neural Network.
A neural network is a computing system comprising highly interconnected and simple processing elements which process the information through their dynamic state response to external inputs. A ‘neuron’ is the fundamental processing element of a neural network. The neural network comprises a large number of neurons working simultaneously to solve specific problems.
This article explains the concept of neural networks and why they are a vital component in the process of deep learning. It also helps to let you know:-
- The advantages of neural networks over conventional techniques
- Working of Neural networks,
- Working of a Neural Network - Training,
- Working of a Neural Network - Learning Rules
- Network models and algorithms of Neural Networks

Why Neural Networks Matter in Deep Learning?
Consider machine learning as a pack horse for processing information, then a carrot that draws the horse forward is the neural network. A system should not be programmed to execute a specific task for it to be able to learn truly; instead, it must be programmed to learn to execute the task.
To accomplish this, the system uses deep learning (a more refined form of machine learning) which is based on neural networks. With the help of neural networks, the system can perceive data patterns independently to learn how to execute a task.
Advantages of Neural Networks over Conventional Techniques
Depending on the strength of internal data patterns and the nature of the application, you can usually expect a network to train well. This is applied to problems where the relationships may be quite nonlinear or dynamic. Very often, the conventional techniques are limited by strict assumptions of variable independence, linearity, normality, etc.
As neural network can capture various types of relationships, it enables the user to relatively easily and quickly model phenomena which otherwise may have been impossible or very difficult to explain.
Working of a Neural Network
Neural networks are modeled after the neuronal structure of the brain’s cerebral cortex but on smaller scales. They are usually organized in layers. Layers are comprised of many nodes which are interconnected and contain an activation function. The patterns are presented to the network through the input layer.
This layer communicates to hidden layers (one or more in number) where the real processing is carried out through a system of weighted connections. Then, the hidden layers(neural hidden layer as shown in the below figure) are connected to an output layer(neural output layer as shown in the below figure) and it is the answer as depicted in the image shown below.
The information flows via a neural network in 2 ways. When the neural network is operating normally (after its training) or learning (during training), the information patterns are fed into the network through input units. These input units will trigger the hidden unit layers and these in turn will arrive at the output units. This design is considered as the feedforward network.
Every unit gets inputs from the units situated on its left. Then, the inputs are multiplied by the connections’ weights they travel along. Each unit sums up every input it receives in its way and the unit triggers the units situated on its right if the sum is more than a certain threshold value. In the below section, we will see how a neural network learns.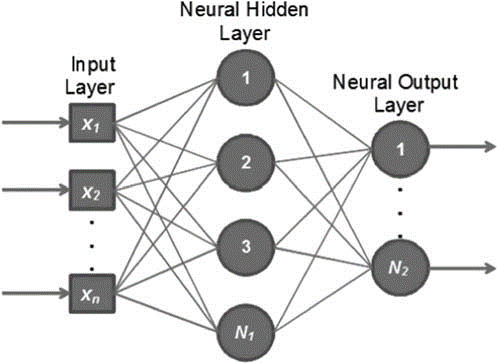
Working of a Neural Network - Training
Training a neuron involves applying a set of steps to adjust the thresholds and weights of its neurons. This kind of adjustment process (also known as learning algorithm) tunes the network so that the outputs of the network are very close to the desired values. The network is ready to be trained once it is structured for a specific application. The initial weights are selected randomly to begin this process. Then, the training or learning starts.
There are two approaches to training - unsupervised and supervised. In supervised training, the network is provided with the desired output in two ways. The first one involves manually grading the performance of the network and the second one is by allocating the desired outputs with the inputs.
In unsupervised training, the network must make sense of the inputs without the help from outside. To put this in familiar terms, let’s consider an instance. Your kids are called supervised if you provide a solution to them during every situation in their life. They are called unsupervised if your kids make decisions on their own out of their understanding.
Most of the neural networks consist of some form of learning rule which alters the weights of connections according to the input patterns that are presented to it. Like their biological counterparts, the neural networks learn by example.
Working of a Neural Network - Learning Rules
Neural networks use various kinds of learning rules. They are as follows.
Hebbian Learning Rule - This learning rule determines, how to alter the weight of nodes of a network.
Perceptron Learning Rule - The network begins its learning by allocating a random value to each weight.
Delta Learning Rule - The modification in a node’s sympatric weight is equal to the multiplication of input and the error.
Correlation Learning Rule - It is the supervised learning.
Outstar Learning Rule - It can be used when it assumes that neurons or nodes in a network are arranged in a layer.
The Delta Learning Rule is often used by the most common class of neural networks known as BPNNs (backpropagation neural networks). Backpropagation implies the backward propagation of error.
Major Neural Network Models
The primary neural network models are as follows.
Multilayer perceptron - This neural network model maps the input data sets onto a set of appropriate outputs.
Radial Basis Function Network - This neural network uses radial basis functions as activation functions.
Both the above models are supervised learning networks, and they are used with one or more dependent variables at the output.
Kohonen Network - This is an unsupervised learning network. This is used for clustering process.
Neural Network Algorithms
As I stated earlier, the procedure used to perform the learning process in a neural network is known as the training algorithm. There are various training algorithms with different performance and characteristics. The major ones are Gradient Descent (used to find the function’s local minimum) and Evolutionary Algorithms (based on the concept of survival of the fittest or natural selection in biology).
Deep Neural Networks
Deep Neural Networks can be thought of as the components of broader applications of machine learning that involve algorithms for regression, classification, and reinforcement learning(a goal-oriented learning depending on interaction with the environment).
These networks are distinguished from single-hidden-layer neural networks by their depth. This implies the number of node layers through which the data passes in a pattern recognition’s multi-step process.
Conventional machine learning depends on shallow networks that are composed of one output and one input layer with at most one hidden layer in-between. Including input and the output, more than three layers qualify as ‘deep’ learning.
A deep neural network is shown in the below figure which has three hidden layers apart from the input and output layers. Hence, deep is a technical and strictly defined term that implies more than one hidden layer. Based on the previous layer’s output, each layer of nodes trains on a different feature set in deep neural networks.
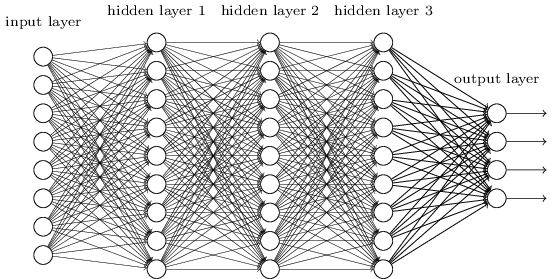
Unlike most traditional machine learning algorithms, deep neural networks carry out automatic feature extraction without intervention. These networks can discover latent structures within unstructured(raw data), unlabeled data which is the majority of data in the world.
A deep neural network which is trained on labeled data can be applied to raw data. This gives the deep neural network access to much more input when compared with machine learning networks. This indicates higher performance as the accuracy of a network depends on how much data it is trained on. Training on more data results in higher accuracy.
Applications of Neural Networks in Python and R
Python Libraries using Neural Networks
Theano
Theano is an open source project released under the BSD license. At its heart, Theano is a compiler for mathematical expressions in Python. It knows how to take your structures and turn them into very efficient code that uses NumPy, efficient native libraries like BLAS and native code (C++) to run as fast as possible on CPUs or GPUs. It uses a host of clever code optimizations to squeeze as much performance as possible from your hardware.
The actual syntax of Theano expressions is symbolic, which can be off putting to beginners used to normal software development. Specifically, expression are defined in the abstract sense, compiled and later actually used to make calculations.
It was specifically designed to handle the types of computation required for large neural network algorithms used in Deep Learning. It was one of the first libraries of its kind and is considered an industry standard for Deep Learning research and development.
TensorFlow
TensorFlow is an open source library for fast numerical computing. It was created and is maintained by Google and released under the Apache 2.0 open source license. The API is nominally for the Python programming language, although there is access to the underlying C++ API.
Unlike other numerical libraries intended for use in Deep Learning like Theano, TensorFlow was designed for use both in research and development and in production systems, not least RankBrain in Google search and the fun Deep Dream project. It can run on single CPU systems, GPUs as well as mobile devices and large scale distributed systems of hundreds of machines.
It’s easy to classify TensorFlow as a neural network library, but it’s not just that. Yes, it was designed to be a powerful neural network library. But it has the power to do much more than that. You can build other machine learning algorithms on it such as decision trees or k-Nearest Neighbors. You can literally do everything you normally would do in numpy! It’s aptly called “numpy on steroids.”
R Libraries using Neural Networks
The caret package is a set of tools for building machine learning models in R. The name “caret” stands for Classification And REgression Training. As the name implies, the caret package gives you a toolkit for building classification models and regression models. Moreover, caret provides you with essential tools for data splitting, pre-processing, feature selection, model tuning using resampling, variable importance estimation as well as other functionality.
There are many different modeling functions in R. Some have different syntax for model training and/or prediction. The package started off as a way to provide a uniform interface the functions themselves, as well as a way to standardize common tasks (such parameter tuning and variable importance).
Caret provides a simple, common interface to almost every machine learning algorithm in R. When using caret, different learning methods like linear regression, neural networks, and support vector machines, all share a common syntax (the syntax is basically identical, except for a few minor changes).
Moreover, additional parts of the machine learning workflow – like cross validation and parameter tuning – are built directly into this common interface. To say that more simply, caret provides you with an easy-to-use toolkit for building many different model types and executing critical parts of the ML workflow. This simple interface enables rapid, iterative modeling. In turn, this iterative workflow will allow you to develop good models faster, with less effort, and with less frustration.
There are many ways to create a neural network. You can code your own from scratch using a programming language such as C# or R. You can also use a tool such as the open source Weka or Microsoft Azure Machine Learning. The R language has an add-on package named nnet that allows you to create a neural network classifier. The nnet R package has been created by Brian Ripley. You can evaluate the accuracy of the model and make predictions using the nnet package.
The functions in the nnet package allow you to develop and validate the most common type of neural network model, i.e, the feed-forward multi-layer perceptron. The functions have enough flexibility to allow the user to develop the best or most optimal models by varying parameters during the training process.
Conclusion
Neural networks have broad applicability to business problems in the real world. They are currently used applied in various industries, and their applicability is getting increased day-by-day. The primary neural network applications include stock exchange prediction, image compression, handwriting recognition, fingerprint recognition, feature extraction, and so on. But, there is a lot more research that is going on in neural networks.
Author: Savaram Ravindra is a writer on Mindmajix.com working on data science related topics. Previously, he was a Programmer Analyst at Cognizant Technology Solutions. He holds a MS degree in Nanotechnology from VIT University