Making binary annotations less boring

Introduction
For a university project, I’m developing a Music recommendation classifier based on the Spotify API. The idea is to recommend new music to the user, based on songs he personally likes or dislikes and on the musical components of the song (speed, tonality, instrumentality and many more).
The preparation of the dataset usually is the most time-consuming part of any machine learning project. This usually consists of gathering the data, cleaning the data, optionally labeling it, feature extraction, splitting it into test and training data. In this post, we are going to talk about the labeling part.
What is labeling?
Labeling or annotation is the act of evaluating the single data points and providing a ground truth for the machine learning model to learn from. It is mostly used in supervised machine learning applications. Let's say you have a dataset of animal pictures and you want your model to learn to identify cats. Then you have to label all the images with the according animals. If there are only two available classes, it’s called binary classification. For example, if you have a spam filter model and you want to decide whether it’s spam (1) or not spam (0).
Never underestimate the importance of a correct labeled dataset. If the ground truth you provide your machine learning algorithm is wrong, you can’t expect the algorithm to outperform human annotators. So, errors you do early on in the annotation process will catch you later in your model evaluations.

In my case, I had to label my dataset, by deciding if I like the song (1) or I dislike the song (0). So my dataset would consist of the different features (energy, danceability, etc.) and the label I manually assigned to the dataset (liked={True, False}).

The Application
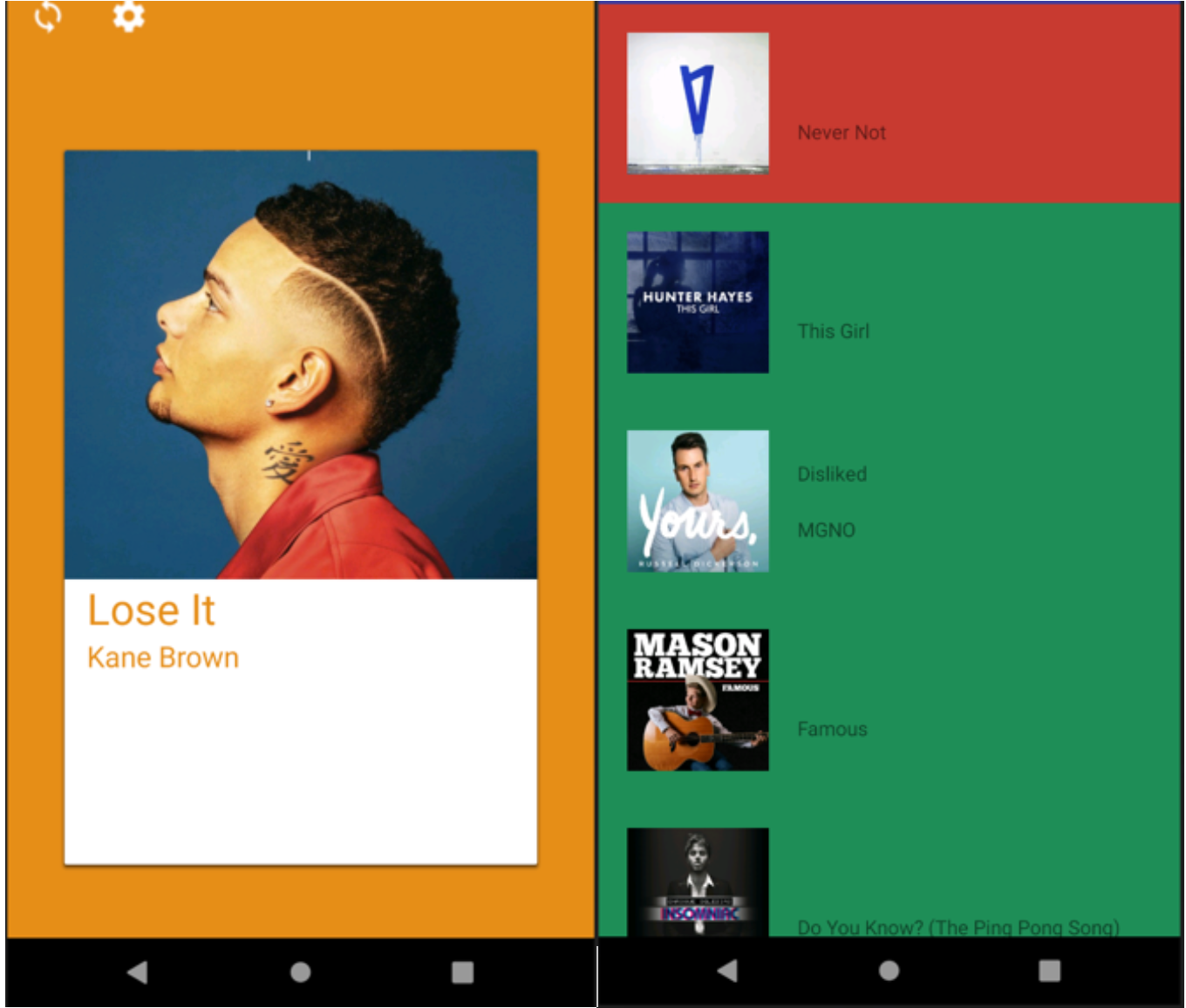
Now to make this boring task a little bit more fun, I developed an android application for binary classification. The reason for this was that I couldn’t motivate myself to sit down and label the songs I listened to recently. With the app, I can just label a few songs when I have some spare time to kill, like if I’m waiting in line, or in public transport. This not only makes it way more fun but also a lot more efficient and I’m able to label a bigger dataset in less time.

Swiping
So how does it work? First, you have to log in with your Spotify account, the app then pulls the last 30 songs you’ve listened to and displays them in card form. From there it’s very similar to Tinder if you swipe the card left you dislike the song, if you swipe right you like it. If you press the card, it will start Spotify on your phone and play the song (only works if Spotify is installed). I provided this feature because I always forgot how the song sounds like, so I could just check really quick.
Additionally, you have an overview, where you can see the songs you swiped and change the current status of the song (liked or disliked) with a tap on the according song.
There is also a screen, where you can select a Spotify playlist of yours. The songs you swipe left will be automatically added to your playlist. I removed this feature because I wasn’t quite sure if I want this functionality in the application. Now it really focuses on the labeling.
The Spotify API
I use the Spotify API because I think their audio analysis for the different songs is pretty accurate and also because I use Spotify daily and thought it would be really interesting to play around with it. Later in my machine learning projects, I will use another music database called MusicBrainz.
To use my application, you need a Spotify account to log into, because we can’t make unauthorized calls to the API. Furthermore, it doesn’t make sense if we can’t pull the songs you have last listened to from your account to swipe on.
I think the API is really easy and fun to use. You are really able to play around with the database and the music.
To play around I added some additional features to my application. If you swipe right or left, you can automatically add them to a playlist (left) or your liked songs (right) in your library. So the app could also be used to quickly add songs to a playlist and even delete them through the overview screen. You can find more information about the Spotify API under
Home | Spotify for Developers
Music, meet code. Powerful APIs, SDKs and widgets for simple and advanced applications.
developer.spotify.com
Firebase as the backend
Now, where does the data go if you swipe a song? I used firebase as the backend for the application because it’s pretty straightforward and it doesn’t need a lot of time to set up a database.

If you don’t know Firebase Realtime Database, it is basically a NoSQL cloud database. The data is stored as JSON and synchronized in realtime to every connected client. Currently, I save only the most relevant data, that is Spotify Track ID, if I liked it or not, the time I swiped the song and some additional information like name and an image for displaying in the application. Otherwise, I had to make another call to the Spotify API and I thought it would be more resourceful doing it like that.
Summary
For me this was a fun little project, to get a little more familiar with the Spotify API which I later used in my machine learning project.
The application could be further developed to make generic labeling or binary classification possible. At the moment, the use case is pretty specific and narrow.
Also, the application could be developed into something like a Spotify playlist adding application, where you could manipulate your playlists and quickly add recently listened songs to a playlist.
I haven’t published the application on the Appstore or somewhere else, because I think the use case is too narrow for the public. If you have any ideas for a use case where more people can benefit from it, I would think about publishing it. So, if you have any ideas let me know.
Also, if you would like to help me improve my machine learning model by providing your own labeled dataset and get personalized recommendations as soon as the application is finished. Please contact me and I would be happy to send you the application so you can start swiping!
If you want to create your own classification application, my project is public on my Github. Feel free to use it!
Written by
Silas Stulz
